
 首 页
首 页曹剑峰:人工智能治理中认知架构建立
引言
当前人工智能(AI)正以前所未有的深度和广度渗透到人类社会与生活的各个层面,已经成为数字经济中重塑产业结构、变革社会互动、驱动经济增长的关键数智化引擎。然而,这股技术变革的新生力量,如同一柄“双刃剑”——在不断释放巨大潜能的同时,也面临关于安全性、公平性、透明度和伦理责任等层面的深刻挑战。
面对这样复杂而关键的议题,亟需建立一个全面、系统且具有前瞻性的治理框架,并以哲科思维为基础不断提高认知水平。本文将从以下三方面展开相关论述。
一 人工智能发展是时代的产物
1.思想的曙光:达特茅斯会议的奠定性贡献

人工智能的纪元,业界广泛公认开启于1956年夏天,在新罕布什尔州达特茅斯学院举行的里程碑式会议。这次为期两个月的暑期学术研讨,汇集了当时十位领域顶尖先驱。他们当时共同提出了一个革命性的研究主题:智能,指的是一组能让机器展现出的行为,其前提是假设人类在同样情境下会如此行动。这一研究主题不仅成就了人工智能(AI)的诞生和命名,而且更精准地描绘了AI的核心目标——模拟、延伸乃至超越人类智能。会议最后的共识中,所勾勒出的七个关键研究领域“共识”,也领导了至今70年人工智能的发展历程,而且还将继续指引未来人工智能的发展方向:
自动计算机:会议指出,未来模拟人脑的瓶颈并非机器的物理容量,而是编写高效程序,以实现从机械计算到自动计算的“形式化”。这也预示了软件工程与计算机科学将成为解锁AI潜能的关键技术,而且进一步强调:算法设计在硬件之上,起到了决定性作用。
语言编程:根据以上参会者前瞻性推测:人类思维的核心是依据规则来进一步操作逻辑词汇与实体概念。这直接指向了逻辑推理与形式语言的重要性,也为后来的高级编程语言(如Prolog)以及自然语言处理(NLP)的发展播下了思想的种子。
神经网络:基于仿生学原理,会议还将“安排一组神经元以形成概念”列为重要议题,并引用了1940年代美国科学家麦卡洛克和皮茨关于神经元模型的研究。这也体现了连接主义思想的早期萌芽,即通过模拟大脑神经元的连接方式来实现学习与认知。这一前瞻性设想,为半个世纪后基于神经网络的深度学习的爆发埋下了伏笔。
计算规模理论:会议认识到,仅仅暴力枚举所有可能性是一种低效行为,进一步提出了对计算效率和复杂性进行理论衡量的必要性。这是对计算复杂性理论的早期呼唤,它指导研究者如何设计更优雅、更高效的算法来解决实际问题,体现了未来“扩散法则”智能“涌现”的影子。
自我改进:对“自我改进”活动的讨论,展现了先驱们对AI终极形态的想象——一种能够自主学习和进化的自治系统。这超越了简单的任务执行,指向了机器学习和自适应系统的核心,是现代强化学习和元学习思想的源头。这一“自主性”原则,也是当下“智能体”时代的早期思想萌芽。
抽象:会议将逻辑学中的“抽象”,视为管理复杂性的核心工具,强调通过选择符号和数据结构来捕捉问题领域的本质特征。这不仅是软件工程的核心原则,更是当前知识本体论和认知科学的基础,是AI理解和处理复杂世界的关键所在。
随机性和创造力:会议大胆猜想,“创造性思维”源于“受控的随机性”。这一洞见极具颠覆性,它认为创新并非完全的确定性推理,而是在直觉引导下的有序探索。这一思想深刻影响了现代AI算法,例如在遗传算法、蒙特卡洛树搜索以及深度学习的Dropout等技术中,随机性都被证明是提升模型性能和避免局部最优的关键要素。
以上达特茅斯会议提出的这七个方向,如同七道深刻的命题,共同构成了人工智能发展的“第一性原理”,为其后70年的技术探索划定了清晰的航向,也必将是其在未来发展中的“指路明灯”。
2.时代的同频共振:算力、算法与算据的三人舞

有了思想的种子,还得有肥沃的土壤。过去这70年,AI能在算力、算法和算据这三者的螺旋式上升中爆发,简直是一场完美的“三人舞”。
先来看算力,从早期的真空管到现在动辄千亿晶体管的GPU集群,摩尔定律不仅没失效,还让训练超大模型变成了现实,这给AI从感知走向认知打下了最硬的物质基础。
再看算法,从早期的符号主义(试图用逻辑穷尽世界),到后来连接主义(神经网络)的复兴,再到Transformer架构的出现,每一次突破都是对“智能”更深层的数学表达。
当然,别忘了算据——也就是数据。现在互联网和移动设备铺天盖地,产生了一个海量数据海洋。没有这些高质量的“燃料”,再精妙的算法也是一堆废代码,再强的算力也只能空转。所以,AI的崛起,是思想火种遇上这“三驾马车”协同并进的必然结果。
人工智能的崛起,是达特茅斯会议所奠定的思想火种,在算力、算法、算据三者协同演进的“完美风暴”中被点燃的时代必然。它不是单一技术的胜利,而是整个信息技术、科技生态集体跃迁的系统性成就,是这个数字时代与时俱进的产物。
二 人工智能还需要广泛的治理活动
1.能力边界的警示:以医疗领域为镜
在某些垂直、高风险的专业领域,当前AI模型的局限性也开始逐步凸显出来,其中医疗卫生领域便是一个绝佳的“观察窗口”。已经有一些核心论文开始详实的记录相关的评测数据,也进一步揭示了LLM在核心临床推理能力上的明显短板。

客观检查建议能力有限:在模拟医生主动收集诊断信息的场景中,所有参加测试模型的表现均不尽如人意。检查建议的最高召回率仅为43.61%(DeepSeek-R1),意味着模型连一半相关的必要检查都未能提出;最高精确率也仅为41.78%(Baichuan-M1),说明其提出的检查建议中包含了大量不相关的内容。这暴露了LLM在主动探究、假设驱动的诊断思维上的根本性缺失,它更倾向于被动回答,不像医生一样,为了验证或排除某个诊断而主动追问。
临床决策推理过程的完整性不足:诊断的可靠性不仅是结论,更在于推理过程的严谨与透明。然而,所有模型在推理的完整性上都存在缺陷,即使表现最佳的模型(Gemini-2.0-FT),其完整性也仅为83.28%,大多数模型在70-80%的区间徘徊。这意味着模型在生成诊断结论时,经常遗漏关键的推理步骤,如鉴别诊断、对症状的动态演化分析等。这种“跳跃式”的推理不仅降低了结论的可信度,更在根本上动摇了其在高风险场景下的可解释性和可靠性。
治疗规划能力显著偏弱:相较于诊断,治疗规划是一个更为复杂的决策过程,需要综合患者的具体生理指标、并发症、药物相互作用、生活质量、个人偏好等多维信息。测试结果显示,所有模型在治疗规划任务上的准确率远低于诊断任务,最高仅为30.65%(Baichuan-M1)。这反映出当前LLM在面对需要深度权衡、个性化定制的复杂决策时,其信息整合与规划能力仍显稚嫩,难以承担提供可靠治疗方案的职责。
多回合交互效率低下:理想的医疗AI应能通过多轮对话,像人类助手一样澄清信息、动态调整。然而,在自由回合的测试中,模型的表现并未如预期般提升,部分甚至出现下降。例如,DeepSeek-R1的检查召回率从单轮的43.61%下降到自由轮的40.67%。这表明模型在动态对话中容易陷入重复提问或逻辑混乱的循环,缺乏有效的对话状态管理和目标导向的沟通策略。
这些医疗临床核心领域的短板,是AI当前能力边界的一个缩影,也进一步警示我们:在将AI部署到任何关键决策场景之前,都必须对其能力进行审慎的、场景化的评估与治理。
2.安全风险的纵深:全栈防御的必要性
大模型的安全问题绝非单一节点的漏洞,而是贯穿其整个生命周期的系统性风险,这要求必须建立“全栈”式的安全治理框架。这个框架至少应涵盖以下层面:

● 基础设施层:涉及训练和部署AI模型的硬件、云平台和网络安全,防范DDoS攻击、数据泄露等基础性威胁。
● 数据层:训练数据的安全是源头。高幻觉率、数据投毒(通过污染训练数据植入后门)、数据隐私泄露(模型无意中记忆并输出敏感信息)以及数据中的偏见和歧视,都可能导致模型产生有害或不公的输出。
● 模型层:这是安全攻防的核心。对抗性攻击(通过对输入进行微小扰动使模型产生错误判断)、模型反演(从模型输出反推训练数据)以及模型本身的安全漏洞,都是严峻的挑战。
● 应用层:在AI模型与用户交互的接口处,面临提示词注入、越狱、生成有害内容、不安全输出处理等风险。如何设计健壮的应用接口和过滤机制至关重要。
● 治理层:超越纯技术层面,建立包括安全审计、红队演练、风险评估、伦理审查、应急响应机制在内的组织化治理流程,是促使安全策略有效落地的保障。
面对这样纵深复杂的安全体系,零散的、被动的修补已无济于事,必须建立一个事前预防、事中监控、事后响应的全方位、常态化治理活动安全全栈,以进一步指导各项治理活动。
3.数据治理的挑战:Data4LLM的全新范式

大模型时代的到来,也使得数据治理(Data4LLM)从传统IT的配角,一跃成为决定AI成败的全新核心课题。其挑战性体现在:
● 质量的极端重要性:“垃圾进,垃圾出”的原则在大模型上被指数级放大。训练数据的准确性、一致性、完整性直接决定了模型能力的基石。
● 规模与多样性的平衡:需要海量数据来覆盖世界的复杂性,但又要保证数据的多样性和代表性,以避免模型偏见和对少数群体的忽视。
● 权属与伦理的合规性:在数据产权日益明晰的今天,如何合法合规地获取和使用数据,尤其是涉及个人隐私的数据,是悬在所有AI企业头上的“达摩克利斯之剑”。
● 可追溯与可解释性:当模型出现错误或偏见时,能否追溯到具体的训练数据源头?如何评估不同数据对模型行为的影响?这些都是数据治理必须回答的问题。
因此,围绕Data4LLM的治理活动,必须从数据采集、清洗、标注、合成、评估到管理的全流程进行重新设计,确保数据这一AI的“血液”是纯净、健康且富有活力的。
三 以哲科思维提高治理认知水平
1.哲学的回响:知识、本体与现象科学的启示
AI治理的深度思考,必然回归到哲学的母题。传统哲学对“知识”与“本体”的探讨,为理解AI的本质提供了根本视角。
● 两大核心问题:哲学一直有两个核心问题——“我们如何理解世界,并获得关于世界的知识”和“实在的本性究竟是什么”。这两个问题与AI治理高度相关。前者关乎AI的认知模式——它是如何“思考”和“学习”的?后者关乎AI与现实世界的关系——它所理解和处理的“世界”,是否与我们所处的实在一致?
● 现象科学的视角:现象学,特别是海德格尔的哲学,提供了一种颠覆性的视角。它强调认知世界的方式是“在世存在”,即人作为主体,沉浸在世界之中,通过实践活动、通过与事物的交互来形成理解。这与传统AI将认知视为脱离情境的符号处理形成鲜明对比。现象学启发我们,未来的AI治理,或许不应只追求模型在封闭测试集中的准确率,而应关注其能否更好地理解情境、意图和常识,能否以一种更“在世”的方式与人类和环境互动。治理的目标,或许是推动AI从一个离身的“计算器”向一个具身的“实践者”演进。
2.科学工程的落地:从本体论到治理架构的跨越
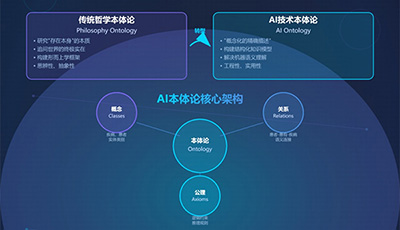
哲学的洞见和科学的框架,最终需要通过工程实践落地到具体的治理活动中。在此,“本体论”扮演了从抽象到具象的关键角色。在AI治理语境下,本体论是指将某个领域(如医疗、金融)的知识、概念、关系、规则用形式化的语言明确定义,构建出一套共享的、机器可理解的知识体系。

这实现了从哲学到工程学的跨越,其内涵与应用可细分为:
(1)智慧金字塔模型的应用:该模型揭示了智能转化的本质是通过算法和算力,对底层数据进行逐层压缩与语义重整化,最终在顶层形成“智慧”。治理活动可以利用这一模型,构建分层的数据与知识治理体系:
● 数据层:通过“本体Transformer”将关系型数据库的数据规范化,形成结构化的“信息”。
● 信息层:通过“知识图谱Transformer”将信息提炼为知识图谱中的实体与关系,形成“知识”。
● 知识层:通过“智能Transformer”将知识压缩为向量,在高维空间实现语义重整化,支撑“智慧”应用。 每一层的压缩都遵循“信息量最大化、信息负载最小化”的原则,确保知识体系的高效与精准。
(2)企业级三层本体架构:在具体实践中,可构建一个三层本体架构来实施治理:

● 领域本体层:定义特定领域的核心概念、属性及其关系。例如,在医疗领域,定义“疾病”、“症状”、“药品”、“检查项目”等及其相互关系。
● 任务/行动决策层:定义业务流程和决策规则。例如,定义“诊断流程”、“治疗方案制定规范”等,将最佳实践和操作规程固化下来。
● 管控治理层:定义伦理、安全、合规等约束性规则。例如,定义“数据隐私保护原则”、“公平性检测标准”、“模型风险阈值”等。
通过这一分层架构,治理活动从外部施加的“紧箍咒”,转变为内嵌于AI系统设计、开发、运行全流程的“基因”。这使得AI的合规性、安全性和可信度在源头上就得到了保障,实现了真正意义上的“可信可治理”。
四 结论
人工智能治理,是一场深远的系统性工程。它始于要读懂AI作为时代产物的历史基因,立足于要看清它能力边界的清醒现实,最后必须升华为用哲科思维构建的高阶认知架构。只有把现象学的反思、IIT(整合型IT)的科学框架和工程化的本体论结合起来,才能造出一个既能鼓励创新又能管住风险的全新治理体系。也只有这样,AI这艘巨轮才能在未来的汪洋大海里,稳稳当当地、持续地造福人类福祉。
作者简介
曹剑峰,上海市卫生健康统计中心副主任(原上海市卫生健康信息中心),担任CHIMA常委、上海市医院协会信息专委会副主任委员、上海市卫生健康信息标委会秘书长等社会职务。拥有30年的医疗健康信息化建设工作经历:1991年进入上海市胸科医院开始从事医院信息化工作;1994年开始参与研发上海第一代医院信息系统(HIS),对医院的业务流程有深刻的理解;2006年进入卫生行政部门——上海市卫生局信息中心,开始参与全市重点项目“公共卫生突发应急工程”、“上海市民健康网工程”的项目实施与管理工作,开始了市、区两级区域医疗信息化的探索;2015年开始负责上海市“社区综改和家庭医生责任制”和“1+1+1”分级诊疗”信息化支撑项目;2017年开始研究大数据DRGS医院病种指数用于公立医院精细化管理方法的探索;2018年开始在上海市拓展“健康云”——“互联网+医疗健康”信息惠民移动服务平台的推广与应用;2019年开始探索建设上海“互联网医院”以及“互联网监管平台”建设。2020年参与组织实施上海市实事工程“支付一件事”,率先实现医保“脱卡信用支付”新模式,同年参与建设青浦“长三角智慧互联网医院”;2021年主持参与上海医疗便捷就医“数字化转型”七大场景中“互联互通互认”与“电子出院小结”两大场景建设;2022年秉持“12512”的理念,组织开展上海卫生健康信息标准化揭榜攻关项目落地。
