
 首 页
首 页走过“数据中台”,回归“数据基座”
从CHIMA 2025大会上看到:
——业务系统不再是中心议题,AI和数据要素才是!
CHIMA 2025大会以“人工智能”与“数据要素”为双核主轴,揭示了医疗数智化转型的深层命题:当算力与模型逐渐普适化,数据价值的爆发正成为行业跃迁的关键引擎。然而,大会现场传递的不仅是愿景,更是反思:头部医院凭借资源禀赋在AI应用中先行破局,而多数医院仍困于数据建设环节,并且行业似乎正陷入数据建设选型的集体迷茫。
本年度CHIMA大会上,也有专家对“数据基座”这一话题探讨与实践,这不禁让我们回忆起多年以前“数据中台”的经历。美好的愿望带领我们创新前行,但是现实效果会让我们即时反思、慎重选择,因此希望能够找到特别适合在AI和数据时代的建设与发展之路。
一,我们源自信息系统基础,如何有效转型对接到数据系统和AI系统?这里有一个架构性选择的问题;而架构性选择更是慎之又慎的重要抉择!
从“数据中心架构”到“数据中台架构”,行业经历了近10年的医院大数据建设探索和实践,但目前医院面临数据价值发挥的关键期,需求侧为何迷茫?市场侧的“数据中台”似乎开始放弃?
“数据中台”概念源于互联网行业(阿里巴巴于2015年首次提出),其设计初衷是在不改变原有信息化架构的基础上,在后台和前台之间加一中间层以解耦,从后台获取数据在中台加工,按业务逻辑封装,统一服务于前台业务。医疗领域的“数据中台”在解决业务问题上成效显著,但面对新时期的数据服务需求,其号称能实现全生命周期的数据管理,架构及项目的复杂性可想而知。医院又如何能在如此复杂的支撑架构中实现数据的自主管控和驾驭?
走过数据中台的实践,才发现问题不仅仅在于应用层面、而是在于基础制约。
基础性问题没有解决好,一切与应用相关的结构和建设都将被影响、被制约。目前业内将这个数据基础性问题——称之为:数据基座。
从各个数据中台建设与应用效果来看,基础性问题不解决,空中楼阁长久不了。信息化项目的建设选型本就是极其复杂和困难的,尤其是传统数据建设项目,动辄几百万甚至上千万,一旦选错,那就是花大代价做无用功。数据建设架构复杂、建设难度高、周期长的项目,在技术高速迭代发展的环境中,极有可能会导致项目完工即为过时的尴尬局面;另外,许多医院数据建设的方案都是“华丽”而又“神秘”的,建设阶段可谓是呕心沥血,通过对复杂技术栈的堆砌来实现整体落地,建成了复杂而又庞大的架构,用起来是知其然而不知其所以然,且使用阶段还要不断地开展复杂的运维工作。
从“数据中心”到“数据中台”,再从“数据中台”回归到“数据基座”建设,这是一个理论到实践、实践到理论的认知提高过程。
今天,我们探讨数据基座的建设问题,就是基于需求谋求创新、回归到“打地基”层面,希望以更好、更高效的数据基座,直接跳过数据中台面向所有的数据需求提供按需的、即席的、全院级别的自主在线数据服务。同时,在AI破局让传统医疗信息化创新效能接近上限的当下,“数据基座”对数据的原子级汇聚与准备,是助力医院乘AI之势,站在新的起点和高度,探索全新的一条HIT发展曲线的必要条件。
二,从数据技术进程,了解不同“数据基座”的适用范围与技术特点

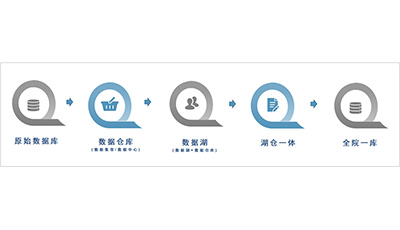
● 数据基座1.0时代:数据仓库
特点:从业务系统直接汇集主题相关数据;存算紧耦合;没有非结构化数据(文本、语音、图像/视频等)。
问题和制约:传统关系型数据库(RDBMS)性能不足。容量资源、数据类型、性能都极为有限。面向主题建设,多仓/多数据集市/多数据中心形成新的分散局面。面向主题域建设的数据不可复用,新需求需建设新仓,局部需求或需要整体重新建模。
● 数据基座2.0时代:数据湖+数据仓库
特点:对比单层数据仓库而言,数据湖的加入实现了各类数据汇聚(数据库+文件);提供各类子集给数据仓库;两层架构复杂;建湖建仓分两步走。
问题和制约:成本投入大,数据质量差、架构复杂难驾驭。湖采用分布式文件存储技术,在获取数据时会受到架构本身的硬件、网络、调度等因素,导致数据需求响应时效性较差。底层技术多采用NoSQL/HDFS数据库,其架构复杂且不具有数据仓库高阶性的特点,在数据获取、存储、流转过程中带来新的数据质量问题。
● 数据基座3.0时代:湖仓一体
特点:提高SQL性能是关键;消除两层结构复杂性;存算分离;分布式存储;HADOOP为主要技术路线。
问题和制约:存算分离在计算引擎的搭建加剧复杂性,湖的本质还是NoSQL/HDFS技术。
● 数据基座新探索实践:全院一库
特点:一体汇聚+动态分级存储;存算一体;既是湖也是仓;HANA内存计算技术:列式压缩存储(压缩倍率高达10-20倍)、亿表查询一秒。
问题和制约:仅汇聚结构化数据,非结构化数据(文本、语言、图像/视频等)需要对接HADOOP。
三,回归本质,方能致远。走过数据中台、回归数据基座,是彻底解除数据结构性制约的有效之路
医疗数据的价值并不取决于其“加工复杂度”,而是取决于其“场景响应力”。从需求来评估选择合适的“数据基座”,正是医疗数据穿越周期、归简务实、实现价值跃迁的关键路径。合适的技术和方案的选择能够将医院的“数据土壤”越养越肥沃,丰富医院的数智生态,助力医院全、快、好、省的发展数智创新,优化服务能力、提高临床水平、强化智能化内涵建设。
CHIMA 2025大会上,人工智能的热度贯穿主论坛与展览现场,从多模态感知到大模型驱动,从科研分析到质控闭环,几乎每一个展位都在讲“AI赋能医疗”。医院管理者们表现出前所未有的兴趣,许多人认为只要“装个模型”,诊断、预警、分析就能立刻上线,似乎AI落地就在眼前。但现实远比想象冷静得多。随着AI模型逐步接入临床、科研、管理等场景,一个核心瓶颈也随之暴露出来:模型再强,也得靠强大的数据支撑。很多方案在实际部署中频频受阻——数据调不出、调不快、调不全,最终导致AI“空转”、无法发挥实效。
以医院全量数据为基础,实现数据的高效敏捷响应,是医疗数据实现价值的关键。合适的技术和方案能丰富医院的数智生态,优化服务能力,让AI从“演示工具”进化为“落地能力”,真正参与到科研闭环、临床决策、管理提效的全链条中。数据基座,才是医疗AI价值落地的真正起点。
相关阅读:
文章一:《私有部署的DeepSeek,怎样敏捷调用医院全量数据?这里隐含着一个大问题!》
文章二:《基于“AI一库”,DeepSeek就可以敏捷调用医院的全量数据!》
文章三:《DeepSeek结合数据的高级应用,首先的挑战是大表和跨库查询!》
(本文由天助盈通供稿)
