
 首 页
首 页阮彤:医疗系统获得大语言模型能力的途径——大语言模型在医疗行业应用系列(二)
大模型生态以令人恐惧的速度发展,每天都会有新的开源模型,新的训练软件包,训练数据,以及形形色色的基于大模型的应用。从大模型开源社区Hugging face,到开源框架LangChain,到Meta的开源模型LLAMA,到可以廉价训练的LORA预训练的方式,以及具有规划和整合能力的AutoGPT,大模型对于普通用户的可获得性越来越强。大模型应用形式越来越丰富,而代价越来越低。
本文将探讨医疗行业如何快速使用大模型的各种能力,体验新技术带来的好处。因为新系统的探索和应用需要时间和各种资源的投入,因此,本文从浅入深,给出了应用落地的顺序,使得最终用户可以以较小的代价受益于技术。
另外,本文仅探讨技术能力,医学以及医疗行业可能涉及到的伦理、安全与政府监管等,包括开源软件商用合法性等,都是重要话题,但此处不进行详细探讨。
一可选技术方案
目前可用的技术方案可以分为三大类:
1.使用现有ChatGPT/GPT4模型,采用插件或其他方式接入大模型,过程中利用大模型的自然语言理解或是自然语言生成能力。
OpenAI提供了官方的插件API,可以用于定制客户化的应用,如检索网络与内部知识库信息,执行科学计算,调用外部工具等。OpenAI目前的插件包含了各种应用,如查询词汇含义,餐厅预定,查询航班、酒店信息,差旅规划,访问电商数据,比价甚至直接下单等。官方演示中包含了ChatGPT接入数学知识引擎Wolfram Alpha,实现精准的数学计算。
最早是使用OpenAI的接口,写一个简单的Prompt完成需要的功能。但这种方法工作量比较大。因此,在插件推出之前,比较流行的是用LangChain框架。该框架面向ChatGPT等大语言模型设计一系列便于集成到实际应用中的接口,降低了在实际场景中部署大语言模型的难度。LangChain框架基于不同的场景,提供了不同的接口。最简单的是通过Prompt Template访问,复杂的如QA Chain、SelfASK Chain等,可以基于外部文档生成问答,或是将大模型的思维链和外部数据源关联起来。另一种方法是使用Agent接口,系统将调用大模型接口,将自然语言指令转化为面向特定应用的调用。此外,LangChain集成了Anthropic、Palm等多种大模型接口,可以在不同的模型之间切换。更加值得注意的是,LangChain和多个向量库、外部知识库集成,为访问外部数据提供了良好的支撑。
2.使用开放模型,在模型上进行持续预训练和指令微调。
很多情况下,由于数据的安全性,技术上的稳定性以及特殊任务要求,领域用户需要将模型部署在自己域内,因此,拥有一个属于自己的大模型成为基本需要。这时候,领域用户可以部署开放模型,或是在开放模型上,基于自己领域任务特殊要求,构造训练数据,再次进行训练。
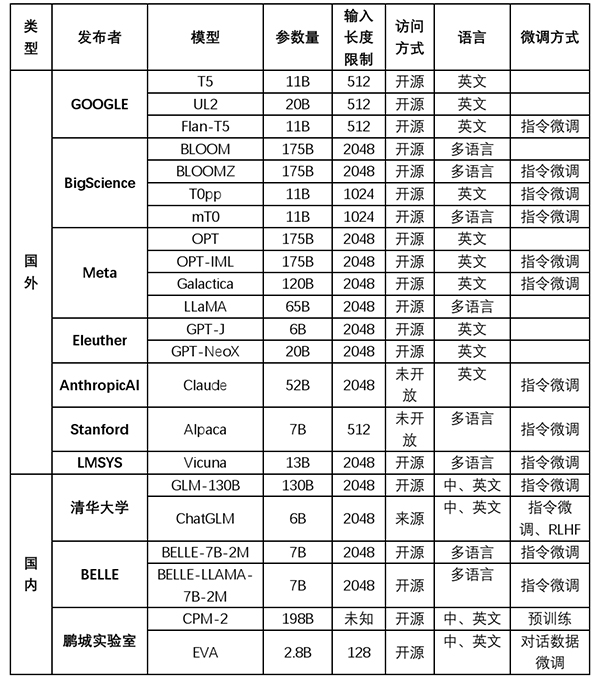
大模型的训练分为三个步骤:首先是预训练,基于目前比较流行的是Decoder或是Encoder-Decoder结构,相比而言,Decoder由于模型简单且速度快,GPT等模型均采用的该架构。这个步骤使得模型能记录海量的知识;其次是有监督微调,即利用用户的监督数据,对模型参数进行调整。这个步骤使得指令可以诱导和激活相应的知识;最后是人类反馈的强化学习,即通过人类的反馈,进行调整模型的结果。这个步骤使得模型的答案与人类的判断更为吻合,但并不增加模型的能力。目前可用的开放模型如下表所示:
表1 目前可用的部分开源模型

其中,BloomZ是在Bloom上微调获得,而ChatGLM是在GLM基础上,以监督微调与人类反馈强化学习等技术经过中英双语训练得到,Alpaca、Belle和Vicuna是在LLAMA微调,分别对应的是英文指令、中文指令以及对话数据。另外,由于LLAMA只用于科研目的,受限比较多,最近Databricks发布了Dolly 2.0,基于ELeutherAI Pythia模型系列,允许各种商用目的。
对于医疗领域,由于数据和应用有自己的特点,可以构造自己的指令数据集合,然后在开源模型进行训练,具体采用的模型可以根据资源以及任务的难易进行选择。数据构造一般有两种方式,一种是通过self-instruct方式,利用ChatGPT的能力获得,一种是利用任务中已有的数据,通过清洗后,自行设计提示模板并将其转换成相应的监督数据。另外,如果领域数据有自己的特性,在微调之前持续预训练可能是需要的,这时候可能需要比较多的计算资源。
3.从头训练一个大模型。对于大型客户,可以自己采集互联网语料,叠加电子病历数据、医术与文献数据,构造纯领域模型。
虽然ChatGPT线路一直将大数据量、大参数量合并算力,作为技术的准入门槛。但是,为什么模型需要那么多语料以及参数,目前还没有公开的解释。同时,正是因为ChatGPT大模型展现的令人震惊的能力与价值,大量科研人员通过数据采样或是蒸馏等策略,减少语言模型所需要的资源。因此,行业顶级用户,从头训练自己的大模型,是可以预期的将来。
二医疗机构尝试前需要考虑的问题
前文说到,电子病历系统、CDR/RDR系统、区域卫生平台、知识库、诊疗、临床科研等系统,利用大模型都可以有比较好的提升。但是从落地角度,到底先尝试哪些呢?本文从代价角度,基于技术和业务门槛,由简单到复杂进行排序。一般来说,采用哪一种解决方案,需要思考下列几个问题:
1.是否需要非开放的专有数据?
如果有专有数据,如电子病历数据,则可能需要放在内部,不能提交给ChatGPT。虽然ChatGPT相关的检索解决方案,可以从技术上比较好的解决检索问题,但电子病历,即使是向量化的电子病历,是否可以提交给ChatGPT,目前也没有共识。
2.是否现有的ChatGPT能力能满足这个应用?
这个问题需要做比较多的测试,因为有时候可能是prompt或是例子写得不合适,导致ChatGPT效果不好,这时候,做合适的Prompt Engineering就可以了。如果不行,就可能需要做指令微调。比如说实体抽取和关系抽取,表面上是ChatGPT能直接满足的,但对于带有数字标号的一些特殊实体,常常会有幻觉出现。
3.如果不能满足,有没有比较大的业务、数据或技术门槛?
技术门槛很难确定,可以看看常见的指令微调数据集合有没有类似的任务,如果有,则可能门槛会比较低一点。比如说电子病历生成,由于基于Prompt的生成任务是大语言模型的一个常见任务,所以虽然可能需要对电子病历文本进行预训练,同时在生成的效果,交互的方式,以及质量的控制等方面都有待探索,但比起互联网问诊还是要方便很多。因为问诊不仅需要有复杂的追问和判断逻辑,需要丰富的知识,而且经常会融合多模态数据,结果又需要高度的精准。因此,相对而言就比较复杂。
4.有几张GPU卡?是A100以上的,还是其他?
如果没有,那就只能使用现有运营的模型,如果有多张4090 GPU卡,根据存储大小,考虑部署开源模型,或是做一些基于LORA模式的指令微调。如果有多张A100,可以考虑较大范围的指令微调以及基于LORA模式的持续训练。
三应用尝试顺序与方案
基于这四个问题的答案,建议应用机构可以按照下列顺序尝试大模型技术。
1.知识库与文献检索系统 使用ChatGPT+LangChain等。由于不涉及内部数据,可以基于现有ChatGPT的LangChain框架以及相关应用直接完成。首先汇集自己常用的医学书籍和文献。其次抽取或解析这些文件,并使用向量库方式,对文档进行语义检索。进一步的,可以根据知识库目标,构造问题与多个问题之间的关联,抽取相关书籍和文献,然后组织成较为结构化的形式,供相关用户浏览。
2.电子病历检索系统 使用开源模型+微调。根据前期作者在部分电子病历上的测试结果,ChatGPT语言模型对电子病历的敏感度是相当高的,只是数据可能不能放到外网。预计基于开源语言模型的搜索,也会比现有的关键词搜索效果要好。如果不能获得很好的效果,进行一些持续训练或者预训练,应该能取得比较好的效果。
3.RDR/区域卫生平台/专病库 采用开源模型+微调/复杂Prompt。这些系统的核心除了检索之外,会有较多的数据清洗与不同类型的数据转换。这个过程一步完成效果可能不会太好。预计需要多个步骤完成,而步骤的分解,以及每个Prompt怎么写,需要进一步实验。
4.电子病历录入 采用开源模型+微调/复杂Prompt。有了很好的语义检索和数据转换功能,电子病历录入就可以集中在内容的撰写,而不是格式的要求上。基于Prompt生成会有幻觉现象,另外,电子病历语言有自己的风格,不同专科电子病历也有特定的要求,如何将这种要求同时让医生和机器了解,需要挑选更为经典的用例,更多的微调以及比较好的Prompt设计。
5.临床科研 采用ChatGPT/开源模型+类AutoGPT框架。这个方向前期在于问题解析和调研,中期在于获取数据以及数据分析,后期在于基于数据的论文撰写。任务有较大的复杂度和各种整合要求,但由于本身对精准度要求并不高,同时也可以有用户的交互,因此准入门槛并不高。这个工作早期可以也通过ChatGPT的各种软件拼接完成。
6.决策支持系统 采用开源模型+微调+外接知识库+推理+图像OCR解析+长上下文。如前文所说,决策系统类型丰富,涉及到的技术点较多,可能还会补充各种检查报告结果,对于普通机构来说,可以在特定决策应用上,比如,预问诊、体检报告阅读,或是特定专科上进行尝试。
与上述任务相关的,是上述任务效果的评估。目前电子病历检索、数据清洗与转换、电子病历录入、决策支持等,都缺乏合适的判断标准,以及相应的标准数据集合进行测试。特别的,对于电子病历录入,还需要通过大规模的RLHF进行提升。而对于决策支持,需要提高决策过程的可解释性,才能真正的让医生和病人信服。
四总结
前文给出了由易到难的尝试次序,对于医疗机构来说,可以按照这个次序进行技术实验。对于企业,需要结合自己的优势业务进行实验。对于研发机构,在日新月异的技术前面,尽量选择门槛较深的方向进行研究。我们将在后续的文章中,逐步给出每类系统的方案或是核心功能演示。
作者简介
阮彤,CHIMA委员,华东理工大学信息科学与工程学院计算机系,博导,教授。现任华东理工大学计算机技术研究所所长,自然语言处理与大数据挖掘实验室主任。长期从事自然语言处理、知识图谱、医学人工智能等方面的研究。
